搜索到
16
篇与
的结果
-
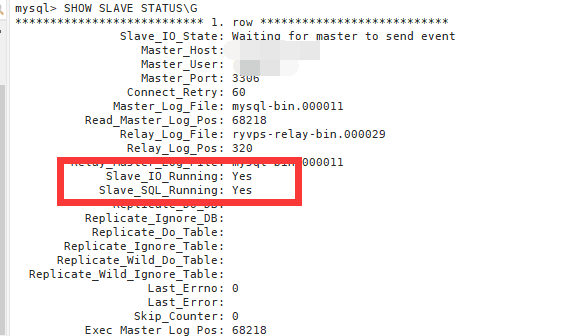
 Mysql主从复制配置教程 MySQL 主从复制配置教程在本教程中,我们将详细介绍如何配置 MySQL 主从复制,以实现数据的高可用性和负载均衡。我们将从主数据库(Master)和从数据库(Slave)的配置开始,逐步完成整个过程。1. 环境准备主数据库(Master): 192.168.1.10从数据库(Slave): 192.168.1.100MySQL 版本: 5.7 或更高版本2. 配置主数据库(Master)2.1 编辑 MySQL 配置文件在主数据库上编辑 MySQL 配置文件(通常是 /etc/my.cnf 或 /etc/mysql/my.cnf),添加以下配置:[mysqld] server-id=1 log_bin=/var/log/mysql/mysql-bin.log binlog_do_db=your_database_nameserver-id: 主数据库的唯一标识,必须是一个唯一的正整数。log_bin: 二进制日志文件的路径。binlog_do_db: 指定需要复制的数据库名称。2.2 重启 MySQL 服务保存配置文件后,重启 MySQL 服务以应用更改:sudo systemctl restart mysql2.3 创建复制用户在主数据库上创建一个用于复制的用户,并授予相应的权限:CREATE USER 'user'@'%' IDENTIFIED BY 'your_password'; GRANT REPLICATION SLAVE ON *.* TO 'user'@'%'; FLUSH PRIVILEGES;2.4 获取二进制日志文件和位置在主数据库上执行以下命令,获取当前的二进制日志文件和位置:FLUSH TABLES WITH READ LOCK; SHOW MASTER STATUS;记录 File 和 Position 的值,稍后在从数据库上配置时会用到。UNLOCK TABLES;3. 配置从数据库(Slave)3.1 编辑 MySQL 配置文件在从数据库上编辑 MySQL 配置文件,添加以下配置:[mysqld] server-id=2 relay_log=/var/log/mysql/mysql-relay-bin.log log_bin=/var/log/mysql/mysql-bin.log binlog_do_db=your_database_nameserver-id: 从数据库的唯一标识,必须是一个唯一的正整数。relay_log: 中继日志文件的路径。log_bin: 二进制日志文件的路径。binlog_do_db: 指定需要复制的数据库名称。3.2 重启 MySQL 服务保存配置文件后,重启 MySQL 服务以应用更改:sudo systemctl restart mysql3.3 配置从数据库连接主数据库在从数据库上执行以下命令,配置从数据库连接主数据库:CHANGE MASTER TO MASTER_HOST='192.168.1.10', MASTER_USER='user', MASTER_PASSWORD='your_password', MASTER_LOG_FILE='mysql-bin.000011', MASTER_LOG_POS=2397;MASTER_HOST: 主数据库的 IP 地址。MASTER_USER: 用于复制的用户名。MASTER_PASSWORD: 用于复制的用户密码。MASTER_LOG_FILE: 主数据库的二进制日志文件名。MASTER_LOG_POS: 主数据库的二进制日志位置。3.4 启动从数据库复制在从数据库上启动复制进程:START SLAVE;3.5 检查从数据库状态在从数据库上执行以下命令,检查复制状态:SHOW SLAVE STATUS\G确保 Slave_IO_Running 和 Slave_SQL_Running 都为 Yes,并且 Last_Error 为空。4. 处理复制错误如果在复制过程中遇到错误,可以使用以下命令跳过错误并继续复制:STOP SLAVE; SET GLOBAL SQL_SLAVE_SKIP_COUNTER = 1; START SLAVE;5. 验证复制在主数据库上进行一些数据操作(如插入、更新、删除),然后在从数据库上检查数据是否同步。参考资料MySQL 官方文档MySQL 主从复制配置指南
Mysql主从复制配置教程 MySQL 主从复制配置教程在本教程中,我们将详细介绍如何配置 MySQL 主从复制,以实现数据的高可用性和负载均衡。我们将从主数据库(Master)和从数据库(Slave)的配置开始,逐步完成整个过程。1. 环境准备主数据库(Master): 192.168.1.10从数据库(Slave): 192.168.1.100MySQL 版本: 5.7 或更高版本2. 配置主数据库(Master)2.1 编辑 MySQL 配置文件在主数据库上编辑 MySQL 配置文件(通常是 /etc/my.cnf 或 /etc/mysql/my.cnf),添加以下配置:[mysqld] server-id=1 log_bin=/var/log/mysql/mysql-bin.log binlog_do_db=your_database_nameserver-id: 主数据库的唯一标识,必须是一个唯一的正整数。log_bin: 二进制日志文件的路径。binlog_do_db: 指定需要复制的数据库名称。2.2 重启 MySQL 服务保存配置文件后,重启 MySQL 服务以应用更改:sudo systemctl restart mysql2.3 创建复制用户在主数据库上创建一个用于复制的用户,并授予相应的权限:CREATE USER 'user'@'%' IDENTIFIED BY 'your_password'; GRANT REPLICATION SLAVE ON *.* TO 'user'@'%'; FLUSH PRIVILEGES;2.4 获取二进制日志文件和位置在主数据库上执行以下命令,获取当前的二进制日志文件和位置:FLUSH TABLES WITH READ LOCK; SHOW MASTER STATUS;记录 File 和 Position 的值,稍后在从数据库上配置时会用到。UNLOCK TABLES;3. 配置从数据库(Slave)3.1 编辑 MySQL 配置文件在从数据库上编辑 MySQL 配置文件,添加以下配置:[mysqld] server-id=2 relay_log=/var/log/mysql/mysql-relay-bin.log log_bin=/var/log/mysql/mysql-bin.log binlog_do_db=your_database_nameserver-id: 从数据库的唯一标识,必须是一个唯一的正整数。relay_log: 中继日志文件的路径。log_bin: 二进制日志文件的路径。binlog_do_db: 指定需要复制的数据库名称。3.2 重启 MySQL 服务保存配置文件后,重启 MySQL 服务以应用更改:sudo systemctl restart mysql3.3 配置从数据库连接主数据库在从数据库上执行以下命令,配置从数据库连接主数据库:CHANGE MASTER TO MASTER_HOST='192.168.1.10', MASTER_USER='user', MASTER_PASSWORD='your_password', MASTER_LOG_FILE='mysql-bin.000011', MASTER_LOG_POS=2397;MASTER_HOST: 主数据库的 IP 地址。MASTER_USER: 用于复制的用户名。MASTER_PASSWORD: 用于复制的用户密码。MASTER_LOG_FILE: 主数据库的二进制日志文件名。MASTER_LOG_POS: 主数据库的二进制日志位置。3.4 启动从数据库复制在从数据库上启动复制进程:START SLAVE;3.5 检查从数据库状态在从数据库上执行以下命令,检查复制状态:SHOW SLAVE STATUS\G确保 Slave_IO_Running 和 Slave_SQL_Running 都为 Yes,并且 Last_Error 为空。4. 处理复制错误如果在复制过程中遇到错误,可以使用以下命令跳过错误并继续复制:STOP SLAVE; SET GLOBAL SQL_SLAVE_SKIP_COUNTER = 1; START SLAVE;5. 验证复制在主数据库上进行一些数据操作(如插入、更新、删除),然后在从数据库上检查数据是否同步。参考资料MySQL 官方文档MySQL 主从复制配置指南 -
Hyper-v安全组 # 定义虚拟机名称 $vmName = "kvm11599" # 添加新的 ACL 规则 # Inbound Allow ICMP Add-VMNetworkAdapterExtendedAcl -VMName $vmName -Direction Inbound -Action Allow -LocalIPAddress 'ANY' -RemoteIPAddress 'ANY' -LocalPort 'ANY' -RemotePort 'ANY' -Protocol 1 -Weight 504 -Stateful $false Write-Host "已添加 Inbound Allow ICMP 规则" # Outbound Deny all Add-VMNetworkAdapterExtendedAcl -VMName $vmName -Direction Outbound -Action Deny -LocalIPAddress '*' -RemoteIPAddress 'ANY' -LocalPort 'ANY' -RemotePort 'ANY' -Protocol 'ANY' -Weight 501 -Stateful $false Write-Host "已添加 Outbound Deny all 规则" # Outbound Allow all Add-VMNetworkAdapterExtendedAcl -VMName $vmName -Direction Outbound -Action Allow -LocalIPAddress 'ANY' -RemoteIPAddress 'ANY' -LocalPort 'ANY' -RemotePort 'ANY' -Protocol 'ANY' -Weight 504 -Stateful $false Write-Host "已添加 Outbound Allow all 规则" # Outbound Allow TCP Add-VMNetworkAdapterExtendedAcl -VMName $vmName -Direction Outbound -Action Allow -LocalIPAddress 'ANY' -RemoteIPAddress 'ANY' -LocalPort 'ANY' -RemotePort 'ANY' -Protocol 'TCP' -Weight 1 -Stateful $false Write-Host "已添加 Outbound Allow TCP 规则" # Inbound Allow TCP Add-VMNetworkAdapterExtendedAcl -VMName $vmName -Direction Inbound -Action Allow -LocalIPAddress 'ANY' -RemoteIPAddress 'ANY' -LocalPort 'ANY' -RemotePort 'ANY' -Protocol 'TCP' -Weight 1 -Stateful $false Write-Host "已添加 Inbound Allow all 规则" # Outbound Allow all (Weight 503) Add-VMNetworkAdapterExtendedAcl -VMName $vmName -Direction Outbound -Action Allow -LocalIPAddress 'ANY' -RemoteIPAddress 'ANY' -LocalPort 'ANY' -RemotePort 'ANY' -Protocol 'ANY' -Weight 503 -Stateful $false Write-Host "已添加 Outbound Allow all (Weight 503) 规则" # Inbound Deny all Add-VMNetworkAdapterExtendedAcl -VMName $vmName -Direction Inbound -Action Deny -LocalIPAddress '*' -RemoteIPAddress 'ANY' -LocalPort 'ANY' -RemotePort 'ANY' -Protocol 'ANY' -Weight 501 -Stateful $false Write-Host "已添加 Inbound Deny all 规则" #Inbound TCP 22 Add-VMNetworkAdapterExtendedAcl -VMName $vmName -Direction Inbound -Action Allow -LocalIPAddress 'ANY' -RemoteIPAddress 'ANY' -LocalPort '22' -RemotePort 'ANY' -Protocol 'TCP' -Weight 502 -Stateful $false Write-Host "已添加 Inbound 22 TCP 规则" #Inbound UPD 53 Add-VMNetworkAdapterExtendedAcl -VMName $vmName -Direction Inbound -Action Allow -LocalIPAddress '10.15.12.35' -RemoteIPAddress 'ANY' -LocalPort 'ANY' -RemotePort '53' -Protocol 'UDP' -Weight 505 -Stateful $false Write-Host "所有 ACL 规则已成功更新。" 因为单项acl策略 以22端口为例需要设置 同入方向的 远程端口和本地端口才能保证能ssh进去 也能ssh别的机器 Add-VMNetworkAdapterExtendedAcl -VMName $vmName -Direction Inbound -Action Allow -LocalIPAddress 'ANY' -RemoteIPAddress 'ANY' -LocalPort '22' -RemotePort 'ANY' -Protocol 'TCP' -Weight 510 -Stateful $false Add-VMNetworkAdapterExtendedAcl -VMName $vmName -Direction Inbound -Action Allow -LocalIPAddress 'ANY' -RemoteIPAddress 'ANY' -LocalPort 'ANY' -RemotePort '22' -Protocol 'TCP' -Weight 510 -Stateful $false资料来源 微软hyper-v acl
-
CentOS-6.8制作qcow2镜像 [root@localhost ~]# cd /etc/yum.repos.d/ [root@localhost yum.repos.d]# rm -rf * [root@localhost yum.repos.d]# cat /etc/yum.repos.d/CentOS-Base.repo [base] name=CentOS-6.10 - Base - mirrors.aliyun.com failovermethod=priority baseurl=http://mirrors.aliyun.com/centos-vault/6.10/os/$basearch/ gpgcheck=1 gpgkey=http://mirrors.aliyun.com/centos-vault/RPM-GPG-KEY-CentOS-6 #released updates [updates] name=CentOS-6.10 - Updates - mirrors.aliyun.com failovermethod=priority baseurl=http://mirrors.aliyun.com/centos-vault/6.10/updates/$basearch/ gpgcheck=1 gpgkey=http://mirrors.aliyun.com/centos-vault/RPM-GPG-KEY-CentOS-6 #additional packages that may be useful [extras] name=CentOS-6.10 - Extras - mirrors.aliyun.com failovermethod=priority baseurl=http://mirrors.aliyun.com/centos-vault/6.10/extras/$basearch/ gpgcheck=1 gpgkey=http://mirrors.aliyun.com/centos-vault/RPM-GPG-KEY-CentOS-6 #additional packages that extend functionality of existing packages [centosplus] name=CentOS-6.10 - Plus - mirrors.aliyun.com failovermethod=priority baseurl=http://mirrors.aliyun.com/centos-vault/6.10/centosplus/$basearch/ gpgcheck=1 enabled=0 gpgkey=http://mirrors.aliyun.com/centos-vault/RPM-GPG-KEY-CentOS-6 #contrib - packages by Centos Users [contrib] name=CentOS-6.10 - Contrib - mirrors.aliyun.com failovermethod=priority baseurl=http://mirrors.aliyun.com/centos-vault/6.10/contrib/$basearch/ gpgcheck=1 enabled=0 gpgkey=http://mirrors.aliyun.com/centos-vault/RPM-GPG-KEY-CentOS-6```html [root@localhost yum.repos.d]# ls CentOS-Base.repo [root@localhost yum.repos.d]# yum clean all [root@localhost yum.repos.d]# yum makecache [root@localhost yum.repos.d]# ls CentOS-Base.repo [root@localhost ~]# yum install util-linux cloud-utils-growpart parted -y [root@localhost ~]# yum install qemu-guest-agent cloud-init -y [root@localhost ~]# yum install vim curl wget net-tools chrony -y [root@localhost ~]# sed -i 's/disable_root: 1/disable_root: 0/g' /etc/cloud/cloud.cfg [root@localhost ~]# sed -i 's/ssh_pwauth:.*/ssh_pwauth:\ \ 1/g' /etc/cloud/cloud.cfg [root@localhost ~]# sed -i 's/\ \ name: .*/\ \ name: root/g' /etc/cloud/cloud.cfg [root@localhost ~]# sed -i 's/lock_passwd: .*/lock_passwd: false/g' /etc/cloud/cloud.cfg [root@localhost ~]# sed -i 's/gecos: .*/gecos: root/g' /etc/cloud/cloud.cfg [root@localhost ~]# service cloud-init start [root@localhost ~]# chkconfig cloud-init on [root@localhost ~]# service qemu-ga start [root@localhost ~]# chkconfig qemu-ga on [root@localhost ~]# rm ~/* rm: remove regular file `/root/anaconda-ks.cfg'? rm: remove regular file `/root/install.log'? rm: remove regular file `/root/install.log.syslog'? [root@localhost ~]# rm -rf /tmp/* [root@localhost ~]# rm ~/.bash_history [root@localhost ~]# history -c [root@localhost ~]# # 关机实例 #宿主机执行 qemu-img convert -c -O qcow2 /path/old.img.qcow2 /path/new.img.qcow2 # [root@wre-wewrf kvm11425]# qemu-img convert -c -O qcow2 kvm11425-system.qcow2 /home/kvm/images/CentOS-6.8.1607-x64_new.qcow2
-
Ceph 因磁盘故障所引起的HEALTH_ERR 收到客户反馈Ceph集群状态异常 连接集群进行检查root@ceph03:~# ceph -s cluster: id: 8b60db4b-5df4-45e8-a6c1-03395e17eda3 health: HEALTH_ERR 6 scrub errors Possible data damage: 1 pg inconsistent 169 pgs not deep-scrubbed in time 169 pgs not scrubbed in time services: mon: 4 daemons, quorum ceph02,ceph03,ceph04,ceph05 (age 12d) mgr: ceph02(active, since 12d), standbys: ceph03, ceph04 osd: 40 osds: 39 up (since 5h), 39 in (since 5h); 66 remapped pgs data: pools: 2 pools, 2048 pgs objects: 18.48M objects, 70 TiB usage: 239 TiB used, 220 TiB / 459 TiB avail pgs: 1220585/55429581 objects misplaced (2.202%) 1976 active+clean 60 active+remapped+backfill_wait 6 active+remapped+backfilling 5 active+clean+scrubbing+deep 1 active+clean+inconsistent io: client: 4.0 KiB/s rd, 1.5 MiB/s wr, 14 op/s rd, 103 op/s wr recovery: 80 MiB/s, 20 objects/s root@ceph03:~# 根据提示 存在6个scrub错误,这可能导致数据一致性问题。有1个PG标记为不一致,表示可能存在数据损坏或丢失。169个PG未能及时完成深度scrub和常规scrub,这可能影响数据的完整性和可用性。输入ceph health detail 进行详细检查root@ceph03:~# ceph health detail HEALTH_ERR 6 scrub errors; Possible data damage: 1 pg inconsistent; 169 pgs not deep-scrubbed in time; 169 pgs not scrubbed in time [ERR] OSD_SCRUB_ERRORS: 6 scrub errors [ERR] PG_DAMAGED: Possible data damage: 1 pg inconsistent pg 2.19b is active+clean+inconsistent, acting [55,47,54] [WRN] PG_NOT_DEEP_SCRUBBED: 169 pgs not deep-scrubbed in time解决思路:修复不一致的PG:运行命令 ceph pg 2.19b query 查看PG的详细信息,以识别不一致的原因。尝试使用 ceph pg repair 2.19b 修复不一致的PG。请注意,修复过程中可能会增加I/O负载,最好在低峰时段进行。确保所有的OSD都正常运行,检查是否有OSD下线或不响应。检查pg 2.19b中 osd.55 47 54磁盘是否有出现异常 检查发现在03节点上的osd.55出现严重故障root@ceph03:~# dmesg |grep error [ 7.740481] EXT4-fs (dm-9): re-mounted. Opts: errors=remount-ro. Quota mode: none. [831126.792545] sd 0:0:4:0: [sde] tag#1534 Add. Sense: Unrecovered read error [831126.792565] blk_update_request: critical medium error, dev sde, sector 12613179976 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 [831130.200831] sd 0:0:4:0: [sde] tag#1529 Add. Sense: Unrecovered read error [831130.200846] blk_update_request: critical medium error, dev sde, sector 12613182688 op 0x0:(READ) flags 0x0 phys_seg 14 prio class 0 [831134.814213] sd 0:0:4:0: [sde] tag#1483 Add. Sense: Unrecovered read error [831134.814225] blk_update_request: critical medium error, dev sde, sector 12613189064 op 0x0:(READ) flags 0x0 phys_seg 33 prio class 0 [831178.101373] sd 0:0:4:0: [sde] tag#1498 Add. Sense: Unrecovered read error [831178.101394] blk_update_request: critical medium error, dev sde, sector 10611476496 op 0x0:(READ) flags 0x0 phys_seg 24 prio class 0 [831351.913095] sd 0:0:4:0: [sde] tag#1570 Add. Sense: Unrecovered read error [831351.913107] blk_update_request: critical medium error, dev sde, sector 15419569648 op 0x0:(READ) flags 0x0 phys_seg 25 prio class 0 [831399.002169] sd 0:0:4:0: [sde] tag#1758 Add. Sense: Unrecovered read error [831399.002186] blk_update_request: critical medium error, dev sde, sector 10616047688 op 0x0:(READ) flags 0x0 phys_seg 97 prio class 0 [831407.091442] sd 0:0:4:0: [sde] tag#1818 Add. Sense: Unrecovered read error [831407.091461] blk_update_request: critical medium error, dev sde, sector 10616091160 op 0x0:(READ) flags 0x0 phys_seg 7 prio class 0 [831521.899028] sd 0:0:4:0: [sde] tag#1879 Add. Sense: Unrecovered read error [831521.899044] blk_update_request: critical medium error, dev sde, sector 12620843200 op 0x0:(READ) flags 0x0 phys_seg 2 prio class 0 [831530.016826] sd 0:0:4:0: [sde] tag#1815 Add. Sense: Unrecovered read error [831530.016838] blk_update_request: critical medium error, dev sde, sector 12620884800 op 0x0:(READ) flags 0x0 phys_seg 34 prio class 0 [831594.377511] sd 0:0:4:0: [sde] tag#1521 Add. Sense: Unrecovered read error [831594.377531] blk_update_request: critical medium error, dev sde, sector 10619805632 op 0x0:(READ) flags 0x0 phys_seg 50 prio class 0 [831599.211869] sd 0:0:4:0: [sde] tag#1857 Add. Sense: Unrecovered read error [831599.211874] blk_update_request: critical medium error, dev sde, sector 10619820608 op 0x0:(READ) flags 0x0 phys_seg 2 prio class 0 [831607.107088] sd 0:0:4:0: [sde] tag#1884 Add. Sense: Unrecovered read error [831607.107097] blk_update_request: critical medium error, dev sde, sector 10619867680 op 0x0:(READ) flags 0x0 phys_seg 6 prio class 0 [831610.973597] sd 0:0:4:0: [sde] tag#1892 Add. Sense: Unrecovered read error [831610.973611] blk_update_request: critical medium error, dev sde, sector 10619871136 op 0x0:(READ) flags 0x0 phys_seg 38 prio class 0 [831670.636650] sd 0:0:4:0: [sde] tag#1895 Add. Sense: Unrecovered read error [831670.636667] blk_update_request: critical medium error, dev sde, sector 12623684528 op 0x0:(READ) flags 0x0 phys_seg 52 prio class 0 [836560.516472] sd 0:0:4:0: [sde] tag#1949 Add. Sense: Unrecovered read error [836560.516477] blk_update_request: critical medium error, dev sde, sector 21702402384 op 0x0:(READ) flags 0x0 phys_seg 8 prio class 0 [836911.696770] sd 0:0:4:0: [sde] tag#2359 Add. Sense: Unrecovered read error [836911.696787] blk_update_request: critical medium error, dev sde, sector 21711922008 op 0x0:(READ) flags 0x0 phys_seg 29 prio class 0 [836949.301804] sd 0:0:4:0: [sde] tag#2325 Add. Sense: Unrecovered read error [836949.301821] blk_update_request: critical medium error, dev sde, sector 21712645720 op 0x0:(READ) flags 0x0 phys_seg 45 prio class 0 [836953.466236] sd 0:0:4:0: [sde] tag#2288 Add. Sense: Unrecovered read error [836953.466242] blk_update_request: critical medium error, dev sde, sector 21712652592 op 0x0:(READ) flags 0x0 phys_seg 17 prio class 0 [836958.247583] sd 0:0:4:0: [sde] tag#2312 Add. Sense: Unrecovered read error [836958.247600] blk_update_request: critical medium error, dev sde, sector 21712668824 op 0x0:(READ) flags 0x0 phys_seg 21 prio class 0 [836965.522676] sd 0:0:4:0: [sde] tag#2353 Add. Sense: Unrecovered read error [836965.522681] blk_update_request: critical medium error, dev sde, sector 21712726416 op 0x0:(READ) flags 0x0 phys_seg 22 prio class 0 [836968.794844] sd 0:0:4:0: [sde] tag#2334 Add. Sense: Unrecovered read error [836968.794863] blk_update_request: critical medium error, dev sde, sector 21712726144 op 0x0:(READ) flags 0x0 phys_seg 24 prio class 0 [837135.238193] sd 0:0:4:0: [sde] tag#2374 Add. Sense: Unrecovered read error [837135.238211] blk_update_request: critical medium error, dev sde, sector 21717129944 op 0x0:(READ) flags 0x0 phys_seg 13 prio class 0 [837139.553614] sd 0:0:4:0: [sde] tag#2369 Add. Sense: Unrecovered read error [837139.553630] blk_update_request: critical medium error, dev sde, sector 21717138816 op 0x0:(READ) flags 0x0 phys_seg 8 prio class 0 [837143.809629] sd 0:0:4:0: [sde] tag#2422 Add. Sense: Unrecovered read error [837143.809636] blk_update_request: critical medium error, dev sde, sector 21717152808 op 0x0:(READ) flags 0x0 phys_seg 3 prio class 0 [837378.533201] sd 0:0:4:0: [sde] tag#2323 Add. Sense: Unrecovered read error [837378.533219] blk_update_request: critical medium error, dev sde, sector 21722984968 op 0x0:(READ) flags 0x0 phys_seg 7 prio class 0 [837385.343446] sd 0:0:4:0: [sde] tag#2326 Add. Sense: Unrecovered read error [837385.343451] blk_update_request: critical medium error, dev sde, sector 21723035760 op 0x0:(READ) flags 0x0 phys_seg 10 prio class 0 [837486.727594] sd 0:0:4:0: [sde] tag#2375 Add. Sense: Unrecovered read error [837486.727613] blk_update_request: critical medium error, dev sde, sector 21725617184 op 0x0:(READ) flags 0x0 phys_seg 20 prio class 0 [995605.782476] sd 0:0:4:0: [sde] tag#3292 Add. Sense: Unrecovered read error [995605.782495] blk_update_request: critical medium error, dev sde, sector 8347884512 op 0x0:(READ) flags 0x0 phys_seg 15 prio class 0 [995787.012868] sd 0:0:4:0: [sde] tag#3300 Add. Sense: Unrecovered read error [995787.012876] blk_update_request: critical medium error, dev sde, sector 8359010136 op 0x0:(READ) flags 0x0 phys_seg 32 prio class 0 [996584.983876] sd 0:0:4:0: [sde] tag#3074 Add. Sense: Unrecovered read error [996584.983881] blk_update_request: critical medium error, dev sde, sector 8400422928 op 0x0:(READ) flags 0x0 phys_seg 25 prio class 0 [996611.976025] sd 0:0:4:0: [sde] tag#3114 Add. Sense: Unrecovered read error [996611.976050] blk_update_request: critical medium error, dev sde, sector 8401488288 op 0x0:(READ) flags 0x0 phys_seg 55 prio class 0 [996684.078459] sd 0:0:4:0: [sde] tag#3081 Add. Sense: Unrecovered read error [996684.078471] blk_update_request: critical medium error, dev sde, sector 8404591280 op 0x0:(READ) flags 0x0 phys_seg 37 prio class 0 [996711.054747] sd 0:0:4:0: [sde] tag#3113 Add. Sense: Unrecovered read error [996711.054765] blk_update_request: critical medium error, dev sde, sector 8405833160 op 0x0:(READ) flags 0x0 phys_seg 2 prio class 0 root@ceph03:~# 将osd.55踢出 等待集群数据平衡后再观察
-
Ceph 简单维护命令详解与示例 Ceph 是一个开源的分布式存储系统,广泛应用于大规模数据存储和处理场景。为了确保 Ceph 集群的稳定运行,运维人员需要掌握一些基本的维护命令。本文将详细介绍一些常用的 Ceph 维护命令,并提供相应的示例。查看集群状态命令:ceph status描述:该命令用于查看 Ceph 集群的整体状态,包括集群的健康状况、OSD 状态、PG 状态等。示例:$ ceph status cluster: id: a7f64266-0894-4f1e-a635-d0aeaca0e993 health: HEALTH_OK services: mon: 3 daemons, quorum a,b,c (age 3h) mgr: a(active, since 3h) osd: 3 osds: 3 up (since 3h), 3 in (since 3h) data: pools: 1 pools, 100 pgs objects: 100 objects, 1.0 GiB usage: 3.0 GiB used, 27 GiB / 30 GiB avail pgs: 100 active+clean详解:cluster:显示集群的唯一标识符和健康状态。services:列出集群中的服务,如 Monitor (mon)、Manager (mgr) 和 OSD (osd)。data:显示数据池、对象、存储使用情况和 PG 状态。查看 OSD 状态命令:ceph osd status描述:该命令用于查看集群中所有 OSD 的状态,包括 OSD 的 ID、状态、权重等。示例:$ ceph osd status +----+------------+-------+-------+--------+---------+--------+---------+-----------+ | id | host | used | avail | wr ops | wr data | rd ops | rd data | state | +----+------------+-------+-------+--------+---------+--------+---------+-----------+ | 0 | node1 | 1.0G | 9.0G | 0 | 0 | 0 | 0 | exists,up | | 1 | node2 | 1.0G | 9.0G | 0 | 0 | 0 | 0 | exists,up | | 2 | node3 | 1.0G | 9.0G | 0 | 0 | 0 | 0 | exists,up | +----+------------+-------+-------+--------+---------+--------+---------+-----------+详解:id:OSD 的唯一标识符。host:OSD 所在的节点。used:OSD 已使用的存储空间。avail:OSD 可用的存储空间。state:OSD 的状态,如 exists,up 表示 OSD 存在且正在运行。查看 PG 状态命令:ceph pg dump描述:该命令用于查看集群中所有 Placement Group (PG) 的状态,包括 PG 的 ID、状态、OSD 分布等。示例:$ ceph pg dump dumped all version 101 stamp 2023-10-01 12:34:56.789 last_osdmap_epoch 100 last_pg_scan 100 PG_STAT OBJECTS MISSING_ON_PRIMARY DEGRADED MISPLACED UNFOUND BYTES LOG DISK_LOG STATE STATE_STAMP VERSION REPORTED UP UP_PRIMARY ACTING ACTING_PRIMARY LAST_SCRUB SCRUB_STAMP LAST_DEEP_SCRUB DEEP_SCRUB_STAMP 1.0 100 0 0 0 0 1024M 32 32 active+clean 2023-10-01 12:34:56.789 101:100 101:100 [0,1,2] 0 [0,1,2] 0 2023-09-30 12:34:56.789 2023-09-30 12:34:56.789 2023-09-30 12:34:56.789详解:PG_STAT:PG 的状态信息。OBJECTS:PG 中的对象数量。STATE:PG 的状态,如 active+clean 表示 PG 处于活动且干净的状态。UP:当前负责该 PG 的 OSD 列表。ACTING:实际负责该 PG 的 OSD 列表。查看 Monitor 状态命令:ceph mon stat描述:该命令用于查看集群中所有 Monitor 的状态,包括 Monitor 的数量和仲裁状态。示例:$ ceph mon stat e3: 3 mons at {a=192.168.1.1:6789/0,b=192.168.1.2:6789/0,c=192.168.1.3:6789/0}, election epoch 10, quorum 0,1,2 a,b,c详解:e3:Monitor 的选举纪元。3 mons:集群中有 3 个 Monitor。quorum 0,1,2:当前的仲裁成员。查看 Manager 状态命令:ceph mgr stat描述:该命令用于查看集群中所有 Manager 的状态,包括 Manager 的数量和活动状态。示例:$ ceph mgr stat { "epoch": 100, "available": true, "num_standbys": 1, "modules": ["dashboard", "restful"], "services": {"dashboard": "https://node1:8443/"} }详解:epoch:Manager 的纪元。available:Manager 是否可用。num_standbys:备用 Manager 的数量。modules:已启用的 Manager 模块。services:Manager 提供的服务,如 Dashboard。查看集群使用情况命令:ceph df描述:该命令用于查看集群的存储使用情况,包括总容量、已使用容量和可用容量。示例:$ ceph df GLOBAL: SIZE AVAIL RAW USED %RAW USED 30 GiB 27 GiB 3.0 GiB 10.00 POOLS: NAME ID USED %USED MAX AVAIL OBJECTS pool1 1 1.0 GiB 3.33% 9.0 GiB 100详解:GLOBAL:集群的整体存储使用情况。POOLS:各个存储池的使用情况。USED:已使用的存储空间。%USED:已使用的存储空间占总容量的百分比。查看集群日志命令:ceph log last描述:该命令用于查看集群的最新日志,帮助排查问题。示例:$ ceph log last 2023-10-01T12:34:56.789 [INF] osd.0: OSD started 2023-10-01T12:34:56.789 [INF] osd.1: OSD started 2023-10-01T12:34:56.789 [INF] osd.2: OSD started详解:日志按时间顺序列出,最新的日志在最前面。查看集群配置命令:ceph config show描述:该命令用于查看集群的配置信息,包括各种参数的当前值。示例:$ ceph config show osd.0 { "osd_data": "/var/lib/ceph/osd/ceph-0", "osd_journal": "/var/lib/ceph/osd/ceph-0/journal", "osd_max_backfills": "10", "osd_recovery_max_active": "5", "osd_recovery_op_priority": "10" }详解:显示指定 OSD 的配置信息。查看集群性能命令:ceph perf dump描述:该命令用于查看集群的性能指标,包括读写操作的延迟、吞吐量等。示例:$ ceph perf dump { "osd": { "0": { "op_w": 0, "op_r": 0, "op_rw": 0, "op_w_latency": 0.0, "op_r_latency": 0.0, "op_rw_latency": 0.0 }, "1": { "op_w": 0, "op_r": 0, "op_rw": 0, "op_w_latency": 0.0, "op_r_latency": 0.0, "op_rw_latency": 0.0 }, "2": { "op_w": 0, "op_r": 0, "op_rw": 0, "op_w_latency": 0.0, "op_r_latency": 0.0, "op_rw_latency": 0.0 } } }详解:op_w:写操作的数量。op_r:读操作的数量。op_w_latency:写操作的平均延迟。op_r_latency:读操作的平均延迟。查看集群告警命令:ceph health detail描述:该命令用于查看集群的健康状态,并提供详细的告警信息。示例:$ ceph health detail HEALTH_WARN 1 pgs degraded; 1 pgs stuck unclean; 1 pgs undersized pg 1.0 is stuck unclean for 10m, current state active+undersized+degraded, last acting [0,1]详解:HEALTH_WARN:集群处于警告状态。pg 1.0:具体的 PG 告警信息。11.查看 OSD 使用情况命令:ceph osd df tree描述:该命令用于查看 Ceph 集群中各个 OSD(Object Storage Daemon)的使用情况,并以树形结构展示。通过该命令,可以直观地了解每个 OSD 的存储使用率、剩余空间等信息。示例:ceph osd df tree ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS TYPE NAME -1 3.00000 300G 100G 100G 0B 100G 200G 33.33 1.00 - root default -3 1.00000 100G 33G 33G 0B 33G 67G 33.00 1.00 - host node1 0 hdd 1.00000 100G 33G 33G 0B 33G 67G 33.00 1.00 222 osd.0 -5 1.00000 100G 33G 33G 0B 33G 67G 33.00 1.00 - host node2 1 hdd 1.00000 100G 33G 33G 0B 33G 67G 33.00 1.00 222 osd.1 -7 1.00000 100G 33G 33G 0B 33G 67G 33.00 1.00 - host node3 2 hdd 1.00000 100G 33G 33G 0B 33G 67G 33.00 1.00 222 osd.2详解:ID:OSD 的唯一标识符。CLASS:OSD 的存储类型(如 HDD、SSD)。WEIGHT:OSD 的权重。SIZE:OSD 的总容量。RAW USE:OSD 的实际使用量。AVAIL:OSD 的可用空间。%USE:OSD 的使用率。PGS:分配给该 OSD 的 Placement Groups 数量。通过 ceph osd df tree 命令,运维人员可以快速了解集群中各个 OSD 的存储使用情况,及时发现并处理存储空间不足的问题。